✅ 탐색적 데이터 분석(EDA)이란?
**탐색적 데이터 분석(EDA, Exploratory Data Analysis)**은 데이터를 수집한 뒤,
분석이나 모델링에 들어가기 전에 데이터의 구조, 특성, 이상점 등을 파악하는 과정입니다.
분석의 품질은 EDA의 깊이에 달려 있습니다.
📦 실습에 사용할 데이터: mtcars
mtcars는 R 내장 데이터로, 1974년 Motor Trend 자동차 잡지에서 발췌한 32대의 자동차 데이터입니다.
주요 변수 소개:
| mpg | 연비 (Miles per Gallon) |
| cyl | 실린더 수 |
| disp | 배기량 |
| hp | 마력 |
| wt | 차량 무게 |
| qsec | 1/4마일 가속 시간 |
| am | 변속기 (0 = 자동, 1 = 수동) |
1️⃣ 데이터 구조 확인
data(mtcars) # R의 내부 데이터 불러오기
str(mtcars) # 데이터 구조

summary(mtcars) # 변수별 요약 통계량

head(mtcars, 5) # 앞부분 일부 출력

🔎 해석 예시:
- mpg는 평균 20.09, 최소 10.4 ~ 최대 33.9로 편차가 크다
- hp는 마력으로, 최대 335까지 존재 → 고성능 차량 포함
- am은 범주형이지만 현재 숫자형으로 저장되어 있음
2️⃣ 결측치(Missing Values) 확인
colSums(is.na(mtcars))

🔍 mtcars에는 결측치가 없지만, 실제 데이터에서는 결측 처리가 중요합니다.
예: na.omit(), imputeTS, mice 패키지 등 활용 가능
3️⃣ 변수별 분포 확인 (히스토그램 & 상자그림)
📊 연속형 변수: 연비(mpg) 분포
hist(mtcars$mpg,
main = "연비 분포 (mpg)",
col = "skyblue",
xlab = "Miles per Gallon")

📦 이상치 탐색: 상자그림(Boxplot)
boxplot(mtcars$hp,
main = "마력(hp)의 분포",
col = "salmon")

4️⃣ 변수 간 관계 탐색 (상관계수 + 산점도)
🔗 수치형 변수 간 상관관계
cor(mtcars[, c("mpg", "hp", "wt", "disp")])
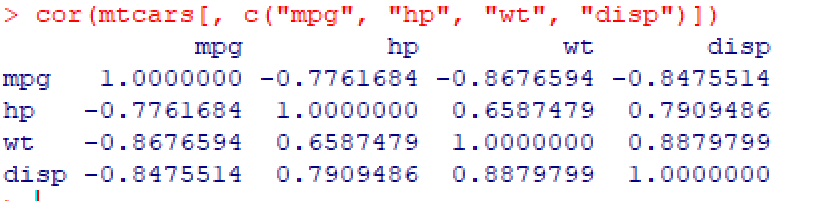
📌 해석:
- mpg와 wt: -0.87 → 차량이 무거울수록 연비가 낮다
- mpg와 hp: -0.78 → 마력이 높을수록 연비가 낮다
🔍 산점도 시각화
plot(mtcars$wt, mtcars$mpg,
xlab = "차량 무게",
ylab = "연비",
main = "차량 무게 vs 연비")
abline(lm(mpg ~ wt, data = mtcars), col = "red")

5️⃣ 범주형 변수 분석: 변속기(am)에 따른 연비 차이
먼저 범주형 변수로 변환:
mtcars$am <- factor(mtcars$am, labels = c("Automatic", "Manual"))
📊 그룹별 평균 비교
tapply(mtcars$mpg, mtcars$am, mean)

📦 그룹별 분포 시각화
boxplot(mpg ~ am, data = mtcars,
col = c("gold", "lightgreen"),
main = "변속기 타입에 따른 연비 비교")

6️⃣ 다변수 관계 시각화 (쌍변수 플롯)
pairs(mtcars[, c("mpg", "disp", "hp", "wt")],
main = "여러 변수 간 관계")

➕ 고급 시각화: GGally 패키지 활용
install.packages("GGally")
library(GGally)
ggpairs(mtcars[, c("mpg", "hp", "wt", "am")])

🎯 마무리 요약
| 1. 데이터 구조 확인 | 변수, 관측치 수, 변수 타입 파악 |
| 2. 결측치 탐색 | is.na()로 누락 데이터 점검 |
| 3. 변수별 분포 확인 | 히스토그램, 상자그림 |
| 4. 상관관계 탐색 | cor(), plot() |
| 5. 범주형 그룹 비교 | 평균, boxplot 활용 |
| 6. 다변수 시각화 | pairs(), ggpairs()로 전체 흐름 파악 |
✍ EDA는 분석의 출발점입니다
EDA를 통해 데이터를 잘 이해하면,
모델 성능 향상, 이상치 제거, 변수 선택 등
모든 분석 단계에서 큰 도움이 됩니다.
📌 데이터와 충분히 대화하세요. 그것이 좋은 분석의 시작입니다.
2025.04.22 - [AI] - 딥러닝 vs 머신러닝, 뭐가 다를까? 한눈에 정리
딥러닝 vs 머신러닝, 뭐가 다를까? 한눈에 정리
인공지능, 머신러닝, 딥러닝… 다 같은 말일까요?최근 뉴스나 블로그를 보면 AI(인공지능), 머신러닝, 딥러닝이라는 단어가 자주 등장합니다.비슷하게 보이지만, 이 세 가지는 서로 다른 개념입
sgorok.com
2025.04.22 - [AI] - 나도 개발자처럼! 코딩 없이 인공지능 앱 만들기
나도 개발자처럼! 코딩 없이 인공지능 앱 만들기
“코딩을 몰라도 AI 앱을 만들 수 있을까?”2025년 현재, 우리는 **‘개발자만의 시대’를 넘어 ‘AI 도구의 시대’**에 살고 있습니다.예전엔 앱 하나 만들기 위해선 복잡한 코딩, 긴 개발 시간, 전
sgorok.com
2025.04.16 - [AI] - R vs Python : 데이터 분석 언어 선택 가이드
R vs Python : 데이터 분석 언어 선택 가이드
"R이 좋을까? Python이 좋을까?" 두 언어 모두 강력한 기능과 넓은 커뮤니티를 가진 최고의 분석 도구입니다. 하지만 각 언어가 가진 특성과 강점은 조금 다르기 때문에, 나의 목적과 환경에 따라
sgorok.com
'AI' 카테고리의 다른 글
| 생성형 AI란? 미래를 바꾸는 인공지능 기술의 모든 것 (1) | 2025.05.15 |
|---|---|
| 메타버스와 NFT의 만남: 디지털 자산 혁명 시작됐다 (0) | 2025.04.30 |
| 인공지능이 바꾸는 교육의 미래, 현실 적용 사례 (0) | 2025.04.27 |
| R을 처음 배우는 당신이 꼭 알아야 할 4가지 기본 문법 (0) | 2025.04.26 |
| AI 스타트업 성공사례 분석 – 미래 산업 인사이트 (0) | 2025.04.25 |



